I recently posted about the new gRPC data portal channel coming in CSLA 5.
I’ve also been working on a data portal channel based on using RabbitMQ as the underlying transport.
Now this might seem odd, because the CSLA .NET data portal is essentially a “synchronous” model, much like HTTP. The caller sends a message to the server, and waits for a response. One of:
- A response message indicating some result (success or failure)
- An exception due to the transport failing
- A timeout due to the server not responsing
This makes sense with gRPC and HTTP, because they both follow that bi-directional communication model. But (by themselves) queues don’t. Queues are “fire and forget”, providing a one-way message protocol.
However, it has been a common practice for decades to use queues for bi-directional messaging through the use of a reply queue.
In this model callers (logical client-side code) sends requests to the data portal by sending a message to the data portal server’s queue.
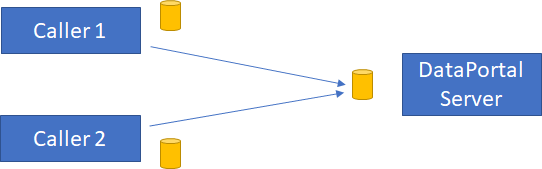
The data portal server processes those messages exactly as though they came in via HTTP or gRPC. The calls are routed to your business code, which can do whatever it wants on the server (typically talk to a database). When your business code is done, the response is sent back to each caller’s respective reply queue.
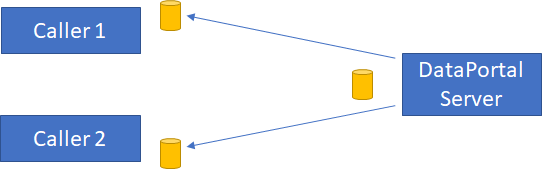
This seems pretty intuitive and straightforward. The various request/response pairs are coordinated using something called a correlation id, which is just a unique value for each original request. Also, each request includes the name of its reply queue, making it easy to respond to the original caller.
The data portal server can handle many inbound requests at the same time, because they are all uniquely identified via correlation id and reply queue. In fact there are some amazing benefits to this approach:
- If the data portal server crashes and comes back up it’ll pick up where it left off - a valuable attribute in an environment such as Kubernetes
- Multiple instances of the data portal server can run at the same time to spread the workload across multiple servers - useful in traditional data centers and in Kubernetes
- Fault tolerance can be achieved by configuring RabbitMQ itself to run in a redundant clustered environment
It is also the case that the caller might be something like a web server. So a given caller might send multiple concurrent requests to the data portal. And that’s fine, because each request has a unique correlation id, allowing replies from the data portal server to be mapped back to the original requester.
The one primarily limitation is that if a caller crashes then its “client-side” state is lost. This is an inherent part of the bi-directional, caller-driven model used by the data portal.
You can think of it as being no different from an HTTP caller (e.g. a browser) shutting down after making a request to a web server and before the server responds. The server may complete its work, but even if the user opens a new browser window they’ll never get the response from the server.
The same thing is true in this implementation of the data portal using RabbitMQ. So it has total parity with HTTP or gRPC in this regard.
The great thing is how CSLA abstracts the use of RabbitMQ, just like it does for HTTP, gRPC, and any other network transport.
Identifying the RabbitMQ Service
Everything assumes you have a RabbitMQ instance running. It might be a single node or a cluster; either way RabbitMQ has an IP address and a port. The data portal also requires that you provide a name for the data portal server queue, and you can optionally manually name the reply queues.
To make this fit within the URL-based model for other transports, CSLA relies on a URI for the RabbitMQ service. It looks like this:
rabbitmq://servername/queuename
And optionally on the client, if you want to manually specify the reply queue name:
rabbitmq://servername/queuename?reply=replyqueuename
In advanced scenarios you can use more of the URI scheme:
rabbitmq://username:password@servername:port/queuename
Think of this like a URL for an HTTP or gRPC endpoint.
Implementing a Client
On the client all that’s needed is:
- Reference the
Csla.Channels.RabbitMqNuGet package (CSLA v5.0.0-R19082201 or higher) - Configure the data portal to use the new channel:
CslaConfiguration.Configure().
DataPortal().
DefaultProxy(typeof(Csla.Channels.RabbitMq.RabbitMqProxy), "rabbitmq://localhost/rmqserver");
This configures the data portal to use the RabbitMQ channel, and to find the server using the provided URI.
Implementing the Server
Unlike with HTTP and gRPC where the server is probably hosted in ASP.NET Core, RabbitMQ servers are usually implemented as a console app. This is ideal for hosting in lightweight containers in Docker or Kubernetes, as there’s no need for the overhead of ASP.NET.
- Create a console app (.NET Core 2.0 or higher)
- Create an instance of the data portal host
- Tell the data portal to start listening for requests
Here’s a complete implementation:
using System;
using System.Threading.Tasks;
namespace rmqserver
{
class Program
{
static async Task Main(string[] args)
{
Console.WriteLine("Start listener; ctl-c to exit");
var host = new Csla.Channels.RabbitMq.RabbitMqPortal("rabbitmq://localhost/rmqserver");
host.StartListening();
await new Csla.Reflection.AsyncManualResetEvent().WaitAsync();
}
}
}
Shared Business Logic
Of course the centerpiece of CSLA .NET is the idea of shared business logic in a common assembly. So any solution would contain the client code as shown above, the server, and a .NET Standard 2.0 Class Library that contains all the business classes that encapsulate business logic.
Both the client and server projects must reference the business class library assembly. That business assembly needs to be available to both client and server code. The data portal takes care of the rest.
In that shared assembly you might have a simple type like this:
using Csla;
using System;
using System.ComponentModel.DataAnnotations;
using System.Threading.Tasks;
namespace ClassLibrary1
{
[Serializable]
public class PersonEdit : BusinessBase<PersonEdit>
{
public static readonly PropertyInfo<int> IdProperty = RegisterProperty<int>(nameof(Id));
public int Id
{
get { return GetProperty(IdProperty); }
set { SetProperty(IdProperty, value); }
}
public static readonly PropertyInfo<string> NameProperty = RegisterProperty<string>(nameof(Name));
[Required]
public string Name
{
get { return GetProperty(NameProperty); }
set { SetProperty(NameProperty, value); }
}
[Create]
private void Create(int id)
{
using (BypassPropertyChecks)
Id = id;
}
[Fetch]
private async Task Fetch(int id)
{
// TODO: get object's data
}
[Insert]
private async Task Insert()
{
// TODO: insert object's data
}
[Update]
private async Task Update()
{
// TODO: update object's data
}
[DeleteSelf]
private async Task DeleteSelf()
{
await Delete(ReadProperty(IdProperty));
}
[Delete]
private async Task Delete(int id)
{
// TODO: delete object's data
}
}
}
The client can interact with this type via the data portal. For example:
var obj = await DataPortal.CreateAsync<PersonEdit>(42);
obj.Name = "Arnold";
if (obj.IsSaveable)
{
await obj.SaveAndMergeAsync();
}
And that’s it. The data portal takes care of relaying that call to the server (in this case via RabbitMQ). The server creates an instance of PersonEdit and invokes the method marked with the Create attribute so the object can invoke a data access layer (DAL) to initialize itself or do whatever is necessary.
In CSLA 5 those create/fetch/insert/update/delete methods can all accept parameters that are provided via dependency injection, but that’s a topic for another blog post. Keep in mind that DI is the appropriate way to gain access to the DAL, and that any interact with databases is encapsulated within the DAL.